|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ECCV 2022 (Oral) |
|
|
 Reconstruction Subset (HuMMan-Recon) |
 Motion Generation Subset (HuMMan-MoGen) [Comming Soon] |
 3D Perception Subset (HuMMan-Point) [Comming Soon] |
 Register for future updates! |
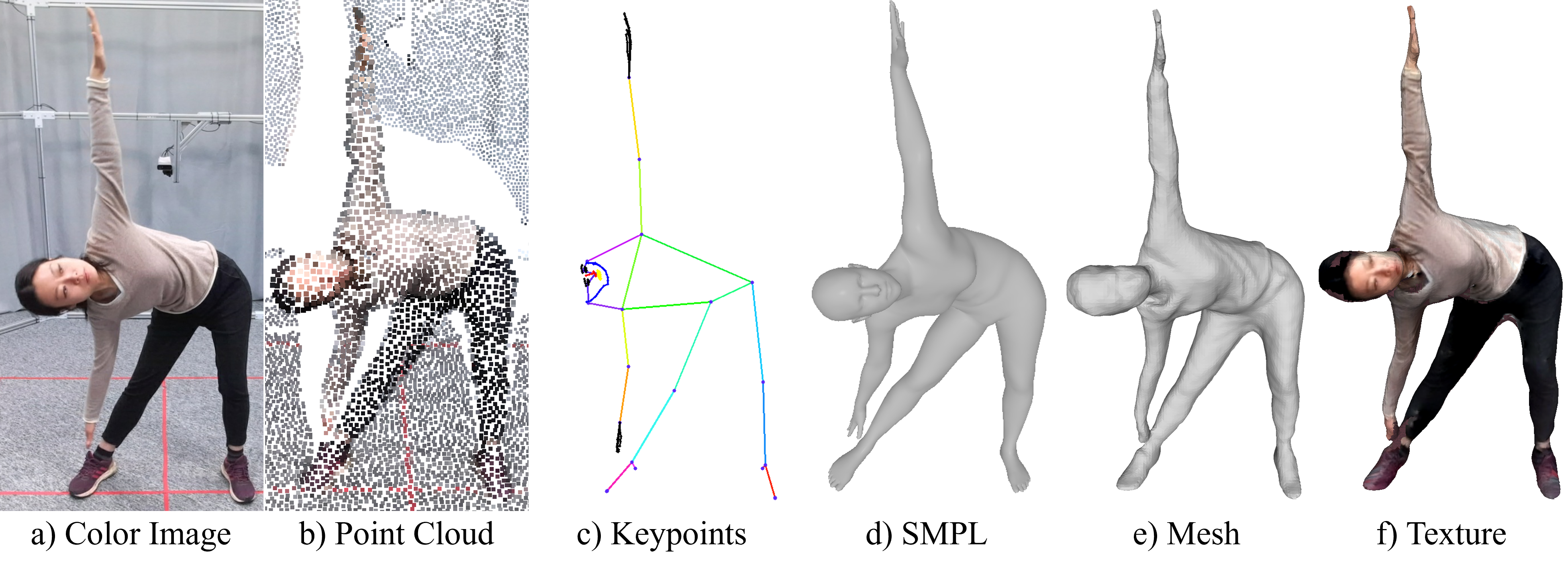
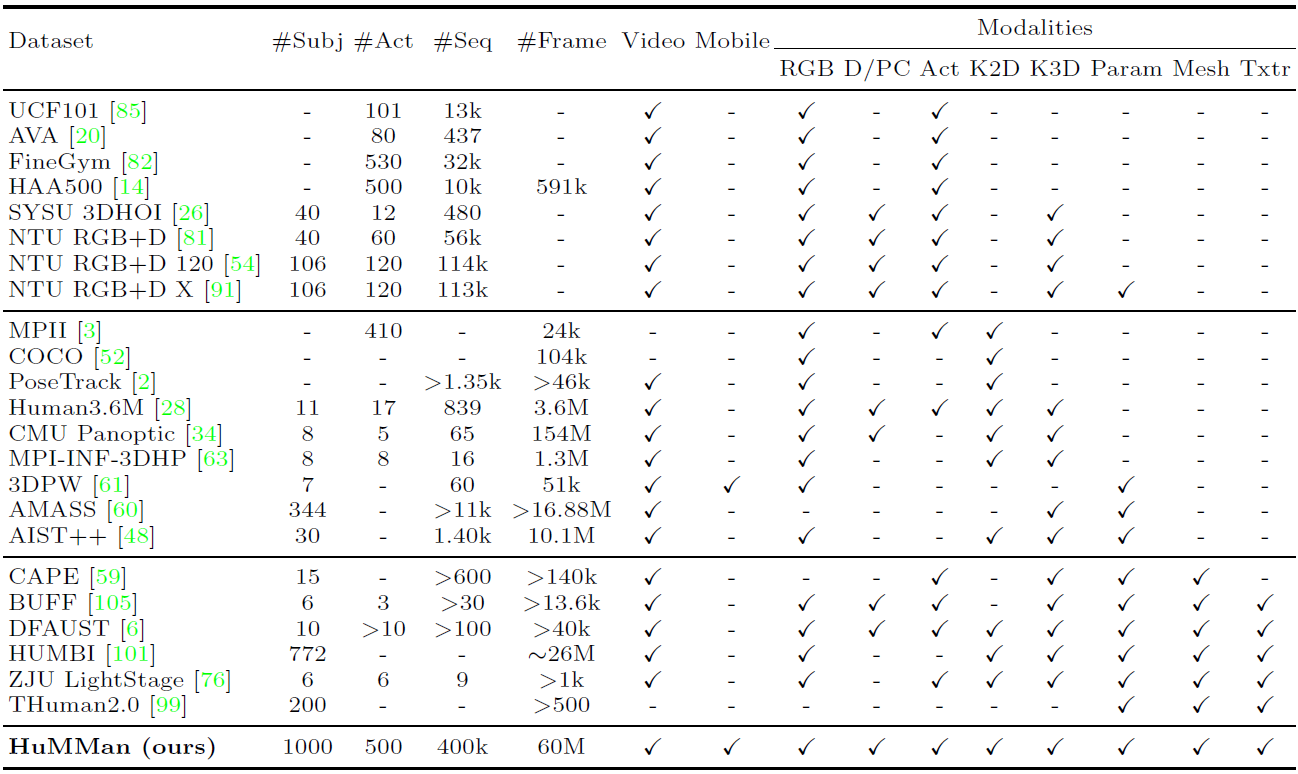
4D human sensing and modeling are fundamental tasks in vision and graphics with numerous applications. With the advances of new sensors and algorithms, there is an increasing demand for more versatile datasets. In this work, we contribute HuMMan, a large-scale multi-modal 4D human dataset with 1000 human subjects, 400k sequences and 60M frames. HuMMan has several appealing properties: 1) multi-modal data and annotations including color images, point clouds, keypoints, SMPL parameters, and textured meshes; 2) popular mobile device is included in the sensor suite; 3) a set of 500 actions, designed to cover fundamental movements; 4) multiple tasks such as action recognition, pose estimation, parametric human recovery, and textured mesh reconstruction are supported and evaluated. Extensive experiments on HuMMan voice the need for further study on challenges such as fine-grained action recognition, dynamic human mesh reconstruction, point cloud-based parametric human recovery, and cross-device domain gaps.
 |
|
|
 |
 [Preprint] |